import subprocess
import sys
# 必要なライブラリをリストにまとめる
required_libraries = [
'json',
'pandas',
'matplotlib',
'pytz',
'ipywidgets',
'numpy',
'seaborn',
'ipyfilechooser',
'plotly'
]
# ライブラリのインストール関数
def install_and_import(library):
try:
__import__(library)
except ImportError:
subprocess.check_call([sys.executable, "-m", "pip", "install", library])
__import__(library)
# 各ライブラリのインストールとインポート
for library in required_libraries:
install_and_import(library)
# インポート文
import json
import pandas as pd
import os
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Yu Mincho', #'Hiragino Kaku Gothic ProN', #'Meiryo', #'Noto Sans CJK JP'
import matplotlib.dates as mdates
import pytz
import ipywidgets as widgets
import numpy as np
import seaborn as sns
import plotly.graph_objects as go
import plotly.express as px
import plotly.io as pio
from ipywidgets import DatePicker, Button, HBox
from matplotlib.lines import Line2D
from pytz import timezone
from IPython.display import display, clear_output
from ipyfilechooser import FileChooser
from datetime import datetime
from datetime import timedelta
print("All libraries are installed and imported successfully.")Sleep Analyze Jupyter Notebook
このスクリプトはGitHubからダウンロードできます。
はじめに
- このノートブックでは、Google Fitのデータを元に睡眠データを分析します
- Google Fitからデータをダウンロードしてください
- Google Fitからデータをダウンロードする方法が分からない方は以下のドキュメント(Google Fitからデータをダウンロードする方法)をご覧ください。
- このノートブックは、筆者のような複数のデバイスを使って睡眠記録をつけている方でも問題なく分析が行えます
- セルは一括で実行せず、1つずつ実行してください
データ分析の流れ
モジュールのインポート
データの取り込み
(手動の睡眠記録がある場合)データセットの選択
(必要であれば)データをCSVファイルとしてエクスポート
アクトグラムを用いた四半期ごとの睡眠記録の可視化

四半期ごとの統計
任意の日付の睡眠記録の可視化
In [2]:
睡眠データの選択
GoogleからダウンロードしたZipファイルを解凍します。
takeout-YYYYMMDDxxxxxx.zipのような名前のZipファイルです
Takeout>Fit>すべてのデータの中にraw_com.google.sleep.segmentという文字列を含むJSONファイルがあるはずなので、それらをすべて任意のフォルダーにコピーします。raw_com.google.sleep.segmentをフォルダ内検索すると便利です
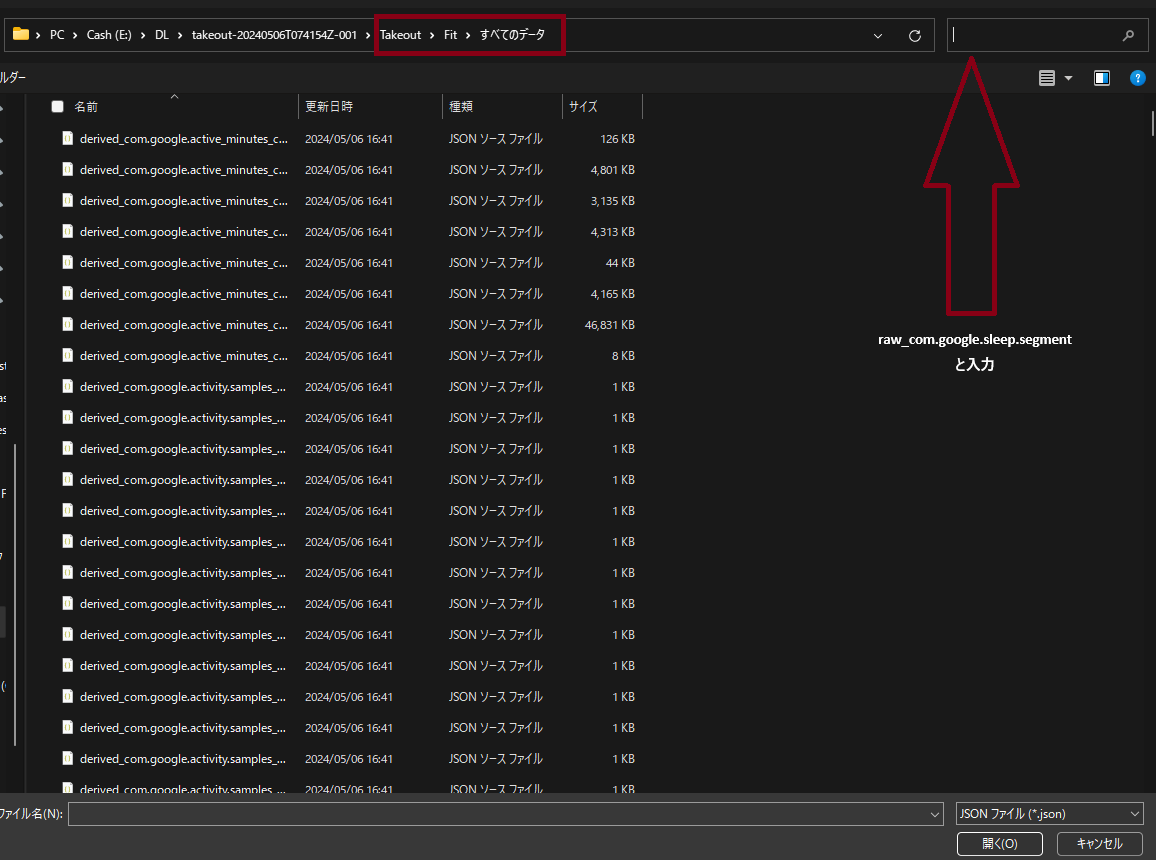
任意のフォルダーにある、全ての睡眠データ(
raw_com.google.sleep.segment)を以下のセルで読み込みます。- あるいは直接、解凍したtakeoutファイルから、
Takeout>Fit>すべてのデータと進み、raw_com.google.sleep.segmentという文字列を含むJSONファイルを選択します(フォルダ内検索を推奨します)
- あるいは直接、解凍したtakeoutファイルから、
In [4]:
# ファイルアップロードウィジェットの作成
uploader = widgets.FileUpload(
accept='.json', # JSONファイルのみを許可
multiple=True, # 複数のファイルをアップロード可能
description='Upload JSON files'
)
file_loading_flag = False
# アップロードされたデータを処理する関数
def process_uploaded_files(change):
global file_loading_flag
# 処理中メッセージを表示
with output:
clear_output()
print("ファイルの処理中です。次のセルには進まないでください。")
sys.stdout.flush() # 出力を即座にフラッシュ
try:
for file_info in change['new']:
print(f"Processing {file_info['name']}")
sys.stdout.flush() # 出力を即座にフラッシュ
content = file_info['content']
import_data = json.loads(content.tobytes().decode('utf-8'))
df = load_and_process_sleep_data(import_data, 'Type of Sleep')
print("ファイルの読み込みが完了しました。次のセルに進んでください")
file_loading_flag = True
with output:
if file_loading_flag is True:
clear_output()
print("ファイルの読み込みが完了しました。次のセルに進んでください。")
sys.stdout.flush() # 出力を即座にフラッシュ
except Exception as e:
with output:
clear_output()
print(f"エラーが発生しました: {e}")
sys.stdout.flush() # 出力を即座にフラッシュ
# JSONデータをDataFrameに変換するための関数
def load_and_process_sleep_data(import_data, type_value):
data_source = import_data['Data Source']
data_points = import_data['Data Points']
df = pd.DataFrame([{
'data_source': data_source,
'start_time_ns': dp['startTimeNanos'],
'end_time_ns': dp['endTimeNanos'],
'sleep_state': dp['fitValue'][0]['value']['intVal'],
'modified_time_ms': dp['modifiedTimeMillis'],
'Type': type_value
} for dp in data_points])
df['start_time'] = pd.to_datetime(df['start_time_ns'], unit='ns')
df['end_time'] = pd.to_datetime(df['end_time_ns'], unit='ns')
return df
# 出力ウィジェットの作成
output = widgets.Output()
# 初期メッセージの表示
with output:
print("ファイルの処理が完了するまで、次のセルには進まないでください")
# アップロードイベントに関数をバインド
uploader.observe(process_uploaded_files, names='value')
# ウィジェットの表示
display(uploader)
display(output)
In [5]:
def parse_datetime_with_format(dt_series):
dt_series_with_ms = dt_series[dt_series.astype(str).str.contains(r"\.\d+")]
dt_series_without_ms = dt_series[~dt_series.astype(str).str.contains(r"\.\d+")]
parsed_with_ms = pd.to_datetime(dt_series_with_ms, format='%Y-%m-%d %H:%M:%S.%f', errors='coerce')
parsed_without_ms = pd.to_datetime(dt_series_without_ms, format='%Y-%m-%d %H:%M:%S', errors='coerce')
return pd.concat([parsed_with_ms, parsed_without_ms]).sort_index()
# アップロードされたファイル名とデータの取得
uploaded_files = uploader.value手動睡眠記録の選択
- 睡眠記録には、自動で睡眠を検知するタイプ(主にスマートウォッチや睡眠マットなど)のものと、スマートフォンアプリなどを用いて手動で睡眠記録の開始・停止をするものの2種類があります
- (このノートブックは、両者に対応しているだけでなく、複数のデバイスを用いて睡眠記録をつけている場合でも問題なく分析を行うことができます)
- もし、手動で睡眠記録を開始・停止している場合、以下のセルでその睡眠データにチェックを入れてください
- (よく分からない場合は特に何もせず、「決定(データを処理)」ボタンを押してください)
In [7]:
# 説明文を表示
description_label = widgets.Label('もし手動で睡眠記録を開始/停止したデータセットがあれば該当するものにチェックを入れてください。')
display(description_label)
# 空のデータフレームを初期化
combined_data = pd.DataFrame()
# ファイルと対応するチェックボックスを表示
checkboxes = []
for file_details in uploader.value:
cb = widgets.Checkbox(
value=False,
description='',
disabled=False
)
label = widgets.Label(file_details['name'])
box = widgets.HBox([cb, label])
checkboxes.append(cb)
display(box)
# プロセスボタンを作成
process_button = widgets.Button(description="決定(データを処理)")
# ボタンのイベントハンドラー
def on_button_clicked(b):
clear_output(wait=True)
global combined_data
for cb, file_details in zip(checkboxes, uploader.value):
filename = file_details['name']
content = file_details['content']
sleep_data = json.loads(content.tobytes().decode('utf-8'))
# チェックボックスの値に応じてデータタイプを設定
type_column_value = 'Manual' if cb.value else 'Auto'
data = load_and_process_sleep_data(sleep_data, type_column_value)
combined_data = pd.concat([combined_data, data], ignore_index=True)
# データ処理後の状態を表示
print("Data processing complete. Dataframe contains:", combined_data.shape[0], "rows.")
process_button.on_click(on_button_clicked)
display(process_button)In [8]:
# 日時データの解析
combined_data['start_time'] = parse_datetime_with_format(combined_data['start_time'])
combined_data['end_time'] = parse_datetime_with_format(combined_data['end_time'])
# データを時系列順にソート
combined_data = combined_data.sort_values(by='start_time')
# 各睡眠データポイントの次の開始時刻を計算
combined_data['next_start_time'] = combined_data['start_time'].shift(-1)
# ギャップを計算(分単位)
combined_data['gap'] = (combined_data['next_start_time'] - combined_data['end_time']).dt.total_seconds() / 60
# 新しいセッションの開始を示すフラグを設定(ギャップが120分以上の場合)
combined_data['new_session_flag'] = (combined_data['gap'] > 119).astype(int)
# session_idを累積和で割り当て
combined_data['session_id'] = combined_data['new_session_flag'].shift(1).fillna(0).cumsum().astype(int)
# 'Type'が'Manual'のデータを抽出して、各セッションの最初のstart_timeをin_bed_timeとして定義
manual_sleep_data = combined_data[combined_data['Type'] == 'Manual']
in_bed_times = manual_sleep_data.groupby('session_id').first().reset_index()
in_bed_times = in_bed_times[['session_id', 'start_time']]
in_bed_times.rename(columns={'start_time': 'in_bed_time'}, inplace=True)
# 全データにin_bed_timeをマージ
combined_data = combined_data.merge(in_bed_times, on='session_id', how='left')
# Extract relevant columns: 'in_bed_time', 'expanded_start_time', 'expanded_end_time', 'majority_sleep_state'
selected_columns_data = combined_data[['data_source', 'Type', 'in_bed_time', 'start_time', 'end_time', 'sleep_state', 'session_id']]
# DataFrameを直接次のステップで使用
sleep_data = selected_columns_data # これが分析や可視化に使われるデータフレーム
# 各セッションの最初のstart_timeと最後のend_timeを取得
session_start_end = combined_data.groupby('session_id').agg({'start_time': 'first', 'end_time': 'last'}).reset_index()
# ミッドスリープタイムを計算
session_start_end['mid_sleep_time'] = session_start_end['start_time'] + (session_start_end['end_time'] - session_start_end['start_time']) / 2
# ミッドスリープタイムの期間を1分に設定
one_minute = timedelta(minutes=1)
session_start_end['mid_sleep_start'] = session_start_end['mid_sleep_time'] - one_minute / 2
session_start_end['mid_sleep_end'] = session_start_end['mid_sleep_time'] + one_minute / 2
# ミッドスリープタイムのデータフレームを作成
mid_sleep_data = pd.DataFrame({
'data_source': 'Mid_sleep_time',
'Type': 'Other',
'in_bed_time': pd.NaT,
'start_time': session_start_end['mid_sleep_start'],
'end_time': session_start_end['mid_sleep_end'],
'sleep_state': 10,
'session_id': session_start_end['session_id']
})
# sleep_dataにミッドスリープタイムのデータを追加
sleep_data = pd.concat([sleep_data, mid_sleep_data], ignore_index=True)睡眠データをCSVファイルとして保存する(任意項目: 保存しなくても問題ありません)
- 以下のセルを実行することで、睡眠データをCSVファイルとして保存することが可能です
- 保存しなくとも分析に問題はありません
- CSVファイルは以下の構成となっています
data_source: インポートしたデータセットの名前です(基本的にはGoogle Fitから取得されたデバイスの名前です)Mid_sleep_time: 算出されたミッドスリープタイム
Type: 基本的にはAutoかManualのどちらかが入りますAuto: 自動で睡眠記録が開始・停止していることを意味しますManual: 手動で睡眠記録が開始・停止していることを意味しますOther: 算出されたミッドスリープタイムであることを意味します
in_bed_time: 手動で睡眠記録を開始している場合、その開始時刻が入りますstart_time: 各睡眠ステージが開始された時刻で、協定世界時(UTC)となっています(日本標準時ではないことに注意してください)end_time: 各睡眠ステージが終了した時刻で、協定世界時(UTC)となっています(日本標準時ではないことに注意してください)sleep_state: Google Fitで定められた睡眠ステージの値(1~6)と、算出したミッドスリープタイム(10)が入りますsession_id: 1回の睡眠ごとに割り振られたIDです(end_timeから次のstart_timeまでの間が2時間以上離れている場合、別の睡眠とみなしています)
睡眠ステージについて
| 睡眠ステージのタイプ | 値 |
|---|---|
| 覚醒(睡眠サイクル中) | 1 |
| 睡眠 | 2 |
| ベッド外 | 3 |
| 浅い睡眠 | 4 |
| 深い睡眠 | 5 |
| レム睡眠 | 6 |
| ミッドスリープタイム | 10 |
(おそらくですが)睡眠ステージ2はデータの信頼性が低く使われていない傾向にあります ミッドスリープタイムはオリジナル(Google Fitのデータ)にはない項目です
In [10]:
# CSVを保存する関数
# ユーザーのデスクトップパスを取得
desktop_path = os.path.join(os.environ['USERPROFILE'], 'Desktop')
# CSVを保存する関数
def save_csv(sleep_data, path):
sleep_data.to_csv(path, index=False)
return f'CSVファイルを {path}に保存しました。'
# 「Save」ボタンの動作を定義
def on_save_button_clicked(b):
with output:
clear_output()
if not fc.selected:
print("CSVファイルの保存先を選択してください")
else:
# ここでDataFrameを保存
result = save_csv(sleep_data, fc.selected) # dfは保存したいDataFrameの変数名
print(result)
# ファイル選択ダイアログを設定
fc = FileChooser(desktop_path)
fc.default_filename = 'sleep_data.csv'
fc.use_dir_icons = True
# 「Save」ボタンの作成
save_button = widgets.Button(
description='Save',
button_style='',
tooltip='Click to save the CSV file',
icon='check'
)
save_button.on_click(on_save_button_clicked)
# 出力エリアを設定
output = widgets.Output()
# ウィジェットを表示
display(fc, save_button, output)アクトグラムを表示するための準備を行うセル
アクトグラムとは、睡眠周期を可視化するグラフのことです。
In [12]:
# 日またぎを処理する関数
def adjust_end_time(start, end):
if end < start:
end += 1440 # 翌日にまたがる場合は24時間分(分)を加算
return end
def convert_to_jst_if_needed(column):
# タイムゾーン情報を確認し、必要に応じて変換を行う
if column.dt.tz is None:
# タイムゾーン情報がない場合、UTCとして解釈し、JSTに変換
return pd.to_datetime(column, utc=True).dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) == 'UTC':
# タイムゾーンがUTCであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) != 'Asia/Tokyo':
# タイムゾーンがJSTでない他のタイムゾーンであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
else:
# 既にJSTであればそのまま返す
return column
def convert_sleep_data_to_jst(sleep_data):
# sleep_dataをコピーしてタイムゾーンを変換
jst_sleep_data = sleep_data.copy()
jst_sleep_data['start_time'] = convert_to_jst_if_needed(jst_sleep_data['start_time'])
jst_sleep_data['end_time'] = convert_to_jst_if_needed(jst_sleep_data['end_time'])
# 明示的に datetime64[ns, Asia/Tokyo] にキャスト
jst_sleep_data['start_time'] = jst_sleep_data['start_time'].astype('datetime64[ns, Asia/Tokyo]')
jst_sleep_data['end_time'] = jst_sleep_data['end_time'].astype('datetime64[ns, Asia/Tokyo]')
return jst_sleep_data
def plot_actogram(sleep_data, start_date, end_date):
# タイムゾーン変換後のデータを取得
jst_sleep_data = convert_sleep_data_to_jst(sleep_data)
# 指定された期間でデータをフィルタリング
filtered_data = jst_sleep_data[
(jst_sleep_data['start_time'] >= pd.Timestamp(start_date).tz_localize('Asia/Tokyo')) &
(jst_sleep_data['end_time'] <= pd.Timestamp(end_date).tz_localize('Asia/Tokyo'))
].copy()
if filtered_data.empty:
print(f"No data available to plot between {start_date} and {end_date}.")
return
# 日またぎを考慮した時間の計算
filtered_data['start_minutes'] = filtered_data['start_time'].apply(lambda dt: dt.hour * 60 + dt.minute)
filtered_data['end_minutes'] = filtered_data.apply(
lambda row: adjust_end_time(row['start_minutes'], row['start_minutes'] + (row['end_time'] - row['start_time']).seconds // 60), axis=1)
color_map = {1: '#e0ffff', 2: '#b3e5fc', 3: '#ff5252', 4: '#03a9f4', 5: '#303f9f', 6: '#ab47bc', 10: 'yellow'}
filtered_data['color'] = filtered_data['sleep_state'].map(color_map)
num_days = max(1, (pd.Timestamp(end_date) - pd.Timestamp(start_date)).days + 1)
fig, ax = plt.subplots(figsize=(20, num_days * 0.4))
for _, row in filtered_data.iterrows():
day_of_week = (row['start_time'] - pd.Timestamp(start_date).tz_localize('Asia/Tokyo')).days
ax.plot([row['start_minutes'], row['end_minutes']], [day_of_week, day_of_week], color=row['color'], alpha=0.7)
ax.plot([row['start_minutes'] + 1440, row['end_minutes'] + 1440], [day_of_week + 1, day_of_week + 1], color=row['color'], alpha=0.7)
ax.set_xlim(0, 2880)
ax.set_ylim(0, num_days)
ax.set_yticks(range(num_days))
ax.set_yticklabels([(pd.Timestamp(start_date).tz_localize('Asia/Tokyo') + pd.Timedelta(days=x)).strftime('%Y-%m-%d') for x in range(num_days)])
ax.set_xlabel('Time')
ax.set_ylabel('Days from Start Date')
plt.title(f'Actogram from {start_date} to {end_date}')
plt.grid(True)
plt.xticks(ticks=[i * 60 for i in range(49)], labels=[f'{(i % 24):02d}:00' if i % 2 == 0 else '' for i in range(49)], rotation=45)
plt.show()
# データセットの範囲確認
jst_sleep_data = convert_sleep_data_to_jst(sleep_data)
start_date = jst_sleep_data['start_time'].min().strftime('%Y-%m-%d')
end_date = jst_sleep_data['start_time'].max().strftime('%Y-%m-%d')
print(f"This dataset contains data from {start_date} to {end_date}.")
↑ に表示されたのが、JSONファイルから読み込まれたデータ範囲です。
This dataset contains data from
YYYY-MM-DDtoYYYY-MM-DD
以下のセルでは、 - JSONファイルに含まれていたデータ期間に応じて、四半期(3ヶ月)ごとにアクトグラムがプロットされます - 1年につき4枚グラフが出るので、含まれているデータ期間が長い場合は、全部のグラフが出力されるまで時間がかかります - 任意の期間のアクトグラムを表示することも可能です
アクトグラムを表示せず、次のセルに進んでも構いません。
In [14]:
# 四半期毎にデータをプロット
start_year = jst_sleep_data['start_time'].dt.year.min()
end_year = jst_sleep_data['start_time'].dt.year.max()
last_date = jst_sleep_data['start_time'].max()
for year in range(start_year, end_year + 1):
for quarter in range(1, 5):
start_month = 3 * quarter - 2
end_month = 3 * quarter
quarter_start_date = pd.Timestamp(year=year, month=start_month, day=1).tz_localize('Asia/Tokyo')
quarter_end_date = pd.Timestamp(year=year, month=end_month, day=1).tz_localize('Asia/Tokyo') + pd.DateOffset(months=1) - pd.DateOffset(days=1)
if quarter_start_date > last_date:
break # この四半期の開始日がデータセットの最後の日を超えている場合はスキップ
if quarter_end_date > last_date:
quarter_end_date = last_date # 四半期の終了日がデータセットの最後の日を超えている場合は調整
plot_actogram(jst_sleep_data, quarter_start_date.strftime('%Y-%m-%d'), quarter_end_date.strftime('%Y-%m-%d'))任意の期間に絞ったアクトグラム
- 任意の期間に絞ったアクトグラムを、ブラウザ上に表示するセルです
- データの期間は四半期(3ヶ月)を推奨しています
- 四半期より長い期間を選択した場合、Y軸の文字が潰れてしまいます
- このセルを実行しなくても問題はありません
In [16]:
# 任意の期間のアクトグラム
def plot_interactive_actogram(sleep_data, start_date, end_date):
# タイムゾーン変換後のデータを取得
jst_sleep_data = convert_sleep_data_to_jst(sleep_data)
# 指定された期間でデータをフィルタリング
filtered_data = jst_sleep_data[
(jst_sleep_data['start_time'] >= pd.Timestamp(start_date).tz_localize('Asia/Tokyo')) &
(jst_sleep_data['end_time'] <= pd.Timestamp(end_date).tz_localize('Asia/Tokyo'))
].copy()
if filtered_data.empty:
print(f"No data available to plot between {start_date} and {end_date}.")
return
# 日またぎを考慮した時間の計算
filtered_data['start_minutes'] = filtered_data['start_time'].apply(lambda dt: dt.hour * 60 + dt.minute)
filtered_data['end_minutes'] = filtered_data.apply(
lambda row: adjust_end_time(row['start_minutes'], row['start_minutes'] + (row['end_time'] - row['start_time']).seconds // 60), axis=1)
color_map = {
1: '#e0ffff', # 覚醒(睡眠サイクル中)
2: '#b3e5fc', # 睡眠
3: '#ff5252', # ベッド外
4: '#03a9f4', # 浅い睡眠
5: '#303f9f', # 深い睡眠
6: '#ab47bc', # レム睡眠
10: 'black' # ミッドスリープタイム(色を強調)
}
sleep_stage_labels = {
1: '覚醒(睡眠サイクル中)',
2: '睡眠',
3: 'ベッド外',
4: '浅い睡眠',
5: '深い睡眠',
6: 'レム睡眠',
10: 'ミッドスリープタイム'
}
filtered_data['color'] = filtered_data['sleep_state'].map(color_map)
num_days = max(1, (pd.Timestamp(end_date) - pd.Timestamp(start_date)).days + 1)
fig = go.Figure()
for sleep_state, color in color_map.items():
sleep_state_data = filtered_data[filtered_data['sleep_state'] == sleep_state]
if not sleep_state_data.empty:
for _, row in sleep_state_data.iterrows():
day_of_week = (row['start_time'] - pd.Timestamp(start_date).tz_localize('Asia/Tokyo')).days
line_width = 7.5 if sleep_state == 10 else 5 # ミッドスリープタイムの場合は線の太さを15に設定
y_offset = 0 if sleep_state == 10 else 0 # ミッドスリープタイムの場合はy座標をさらにオフセット
opacity = 1 if sleep_state == 10 else 0.5 # ミッドスリープタイム以外は透明度を0.3に設定
fig.add_trace(go.Scatter(
x=[row['start_minutes'], row['end_minutes']],
y=[day_of_week + y_offset, day_of_week + y_offset],
mode='lines',
line=dict(color=row['color'], width=line_width),
name=sleep_stage_labels[sleep_state],
text=f"{row['start_time'].strftime('%Y-%m-%d %H:%M')} to {row['end_time'].strftime('%Y-%m-%d %H:%M')}",
hoverinfo='text',
opacity=opacity
))
fig.add_trace(go.Scatter(
x=[row['start_minutes'] + 1440, row['end_minutes'] + 1440],
y=[day_of_week + 1 + y_offset, day_of_week + 1 + y_offset],
mode='lines',
line=dict(color=row['color'], width=line_width),
name=sleep_stage_labels[sleep_state],
text=f"{row['start_time'].strftime('%Y-%m-%d %H:%M')} to {row['end_time'].strftime('%Y-%m-%d %H:%M')}",
hoverinfo='text',
opacity=opacity
))
# 凡例を統合
unique_labels = set()
fig.for_each_trace(lambda trace: trace.update(showlegend=False) if trace.name in unique_labels else unique_labels.add(trace.name))
fig.update_layout(
title=f'Interactive Actogram from {start_date} to {end_date}',
xaxis_title='Time',
yaxis_title='Days from Start Date',
xaxis=dict(
tickmode='array',
tickvals=[i * 60 for i in range(49)],
ticktext=[f'{(i % 24):02d}:00' if i % 2 == 0 else '' for i in range(49)],
range=[0, 2880]
),
yaxis=dict(
tickvals=list(range(num_days)),
ticktext=[(pd.Timestamp(start_date).tz_localize('Asia/Tokyo') + pd.Timedelta(days=x)).strftime('%Y-%m-%d') for x in range(num_days)],
range=[0, num_days],
tickfont=dict(size=10) # Y軸ラベルの文字サイズを小さく
),
hovermode='closest',
legend=dict(
itemsizing='constant'
)
)
pio.write_html(fig, file='sleep_data_plot.html', auto_open=True)
# ウィジェットの作成
start_date_picker = widgets.DatePicker(
description='Start Date',
disabled=False
)
end_date_picker = widgets.DatePicker(
description='End Date',
disabled=False
)
interactive_button = widgets.Button(
description='Plot Interactive Actogram',
button_style='info',
tooltip='Click to plot the interactive actogram',
icon='line-chart'
)
notice_label = widgets.Label(
value='データ範囲は四半期(3ヶ月)程度にしてください。それ以上の期間を指定すると文字が潰れて読めなくなります。また、グラフの作成には少し時間がかかります。'
)
# ボタンがクリックされたときの動作
def on_button_clicked(b):
start_date = start_date_picker.value
end_date = end_date_picker.value
if start_date is not None and end_date is not None:
plot_interactive_actogram(sleep_data, start_date, end_date)
else:
print("Please select both start and end dates.")
interactive_button.on_click(on_button_clicked)
# ウィジェットの表示
display(notice_label, start_date_picker, end_date_picker, interactive_button)睡眠の統計分析を行うセル
以下のセルでは、 1. 四半期ごとの睡眠時間及び睡眠の質の推移の可視化(折れ線グラフ) - 1枚 2. 四半期の範囲で曜日別の睡眠時間及び睡眠の質の可視化(箱ひげ図) - 1年につき4枚 を行います。
含まれているデータ期間が長い場合は、全部のグラフが出力されるまで時間がかかります。 そのため、実行せず、次のセルに進んでも構いません。
In [18]:
def calculate_sleep_quality(sleep_data):
# 各セッションの睡眠時間を計算
session_start_end = sleep_data.groupby('session_id').agg(
start_time=('start_time', 'min'),
end_time=('end_time', 'max')
).reset_index()
session_start_end['sleep_duration_total'] = (session_start_end['end_time'] - session_start_end['start_time']).dt.total_seconds() / 3600
# 深い睡眠の割合を計算
sleep_data['sleep_duration'] = (sleep_data['end_time'] - sleep_data['start_time']).dt.total_seconds() / 3600
deep_sleep_data = sleep_data[sleep_data['sleep_state'] == 5] # 深い睡眠
deep_sleep_duration = deep_sleep_data.groupby('session_id')['sleep_duration'].sum().reset_index()
# 列名を変更
deep_sleep_duration.rename(columns={'sleep_duration': 'sleep_duration_deep'}, inplace=True)
sleep_quality = pd.merge(session_start_end, deep_sleep_duration, on='session_id', how='left')
sleep_quality['sleep_quality'] = sleep_quality['sleep_duration_deep'].fillna(0) / sleep_quality['sleep_duration_total']
return sleep_quality[['session_id', 'sleep_duration_total', 'sleep_quality']]
def calculate_quarterly_sleep_stats(sleep_data):
sleep_quality = calculate_sleep_quality(sleep_data)
sleep_data = pd.merge(sleep_data, sleep_quality, on='session_id')
sleep_data['quarter'] = sleep_data['start_time'].dt.to_period('Q')
quarterly_stats = sleep_data.groupby('quarter').agg(
avg_sleep_time=('sleep_duration_total', 'mean'),
avg_sleep_quality=('sleep_quality', 'mean')
).reset_index()
return quarterly_stats
def plot_quarterly_sleep_stats(quarterly_stats):
fig, ax1 = plt.subplots(figsize=(18, 6))
ax1.set_xlabel('Quarter')
ax1.set_ylabel('Average Sleep Time (hours)', color='tab:blue')
ax1.plot(quarterly_stats['quarter'].astype(str), quarterly_stats['avg_sleep_time'], color='tab:blue', marker='o', label='Avg Sleep Time')
ax1.tick_params(axis='y', labelcolor='tab:blue')
ax2 = ax1.twinx()
ax2.set_ylabel('Average Sleep Quality', color='tab:orange')
ax2.plot(quarterly_stats['quarter'].astype(str), quarterly_stats['avg_sleep_quality'], color='tab:orange', marker='o', linestyle='--', label='Avg Sleep Quality')
ax2.tick_params(axis='y', labelcolor='tab:orange')
fig.tight_layout()
fig.legend(loc='upper left', bbox_to_anchor=(0.1, 0.9))
plt.title('Quarterly Average Sleep Time and Quality')
plt.show()
def calculate_weekly_sleep_stats(sleep_data):
sleep_quality = calculate_sleep_quality(sleep_data)
sleep_data = pd.merge(sleep_data, sleep_quality, on='session_id')
sleep_data['quarter'] = sleep_data['start_time'].dt.to_period('Q')
sleep_data['weekday'] = sleep_data['start_time'].dt.day_name()
weekly_stats = sleep_data.groupby(['quarter', 'weekday']).agg(
avg_sleep_time=('sleep_duration_total', 'mean'),
avg_sleep_quality=('sleep_quality', 'mean')
).reset_index()
return weekly_stats
def plot_weekly_sleep_stats_boxplot(sleep_data_jst):
sleep_quality = calculate_sleep_quality(sleep_data_jst)
sleep_data = pd.merge(sleep_data_jst, sleep_quality, on='session_id')
sleep_data['quarter'] = sleep_data['start_time'].dt.to_period('Q')
sleep_data['weekday'] = sleep_data['start_time'].dt.day_name()
weekdays = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_colors = ['#3498db', '#3498db', '#3498db', '#3498db', '#3498db', '#e74c3c', '#e74c3c'] # 平日は青、土日は赤
weekday_palette = dict(zip(weekdays, weekday_colors))
for quarter in sleep_data['quarter'].unique():
quarter_data = sleep_data[sleep_data['quarter'] == quarter]
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 12))
# 睡眠時間の箱ひげ図
sns.boxplot(x='weekday', y='sleep_duration_total', data=quarter_data, order=weekdays, palette=weekday_palette, ax=ax1, hue='weekday', dodge=False)
ax1.set_title(f'Weekly Sleep Duration for {quarter}')
ax1.set_xlabel('Weekday')
ax1.set_ylabel('Sleep Duration (hours)')
ax1.legend([],[], frameon=False) # レジェンドを非表示にする
# 睡眠の質の箱ひげ図
sns.boxplot(x='weekday', y='sleep_quality', data=quarter_data, order=weekdays, palette=weekday_palette, ax=ax2, hue='weekday', dodge=False)
ax2.set_title(f'Weekly Sleep Quality for {quarter}')
ax2.set_xlabel('Weekday')
ax2.set_ylabel('Sleep Quality')
ax2.legend([],[], frameon=False) # レジェンドを非表示にする
plt.tight_layout()
plt.show()
# データの準備
sleep_data_jst = convert_sleep_data_to_jst(sleep_data)
# 四半期ごとの統計を計算
quarterly_stats = calculate_quarterly_sleep_stats(sleep_data_jst)
# 結果をプロット
plot_quarterly_sleep_stats(quarterly_stats)
# 曜日別の統計を計算
weekly_stats = calculate_weekly_sleep_stats(sleep_data_jst)
# 結果を箱ひげ図でプロット
plot_weekly_sleep_stats_boxplot(sleep_data_jst)任意の日付による、睡眠セッションの可視化
以下のセルでは、ユーザーが指定した日付の睡眠セッション分析し、睡眠ステージの推移をグラフに表示します。
In [20]:
def convert_to_jst_if_needed(column):
# タイムゾーン情報を確認し、必要に応じて変換を行う
if column.dt.tz is None:
# タイムゾーン情報がない場合、UTCとして解釈し、JSTに変換
return pd.to_datetime(column, utc=True).dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) == 'UTC':
# タイムゾーンがUTCであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) != 'Asia/Tokyo':
# タイムゾーンがJSTでない他のタイムゾーンであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
else:
# 既にJSTであればそのまま返す
return column
def convert_sleep_data_to_jst(sleep_data):
# sleep_dataをコピーしてタイムゾーンを変換
sleep_data_jst = sleep_data.copy()
sleep_data_jst['start_time'] = convert_to_jst_if_needed(sleep_data_jst['start_time'])
sleep_data_jst['end_time'] = convert_to_jst_if_needed(sleep_data_jst['end_time'])
if 'in_bed_time' in sleep_data.columns:
sleep_data_jst['in_bed_time'] = convert_to_jst_if_needed(sleep_data_jst['in_bed_time'])
else:
sleep_data_jst['in_bed_time'] = None
# 明示的に datetime64[ns, Asia/Tokyo] にキャスト
sleep_data_jst['start_time'] = sleep_data_jst['start_time'].astype('datetime64[ns, Asia/Tokyo]')
sleep_data_jst['end_time'] = sleep_data_jst['end_time'].astype('datetime64[ns, Asia/Tokyo]')
sleep_data_jst['in_bed_time'] = sleep_data_jst['in_bed_time'].astype('datetime64[ns, Asia/Tokyo]')
return sleep_data_jst
def create_session_data(sleep_data_jst):
# 各セッションの最終 'end_time' を取得して日付に変換
session_dates = sleep_data_jst.groupby('session_id')['end_time'].max().dt.date
session_dates = session_dates.reset_index()
session_dates.rename(columns={'end_time': 'session_date'}, inplace=True)
# 睡眠時間と睡眠潜時の計算
sleep_times = sleep_data_jst.groupby('session_id').agg(
sleep_time=('end_time', lambda x: (x.max() - x.min()).total_seconds() / 3600),
start_time=('start_time', 'min')
)
sleep_times.reset_index(inplace=True)
# 睡眠潜時の計算
sleep_latency = sleep_data_jst.groupby('session_id').apply(
lambda group: calculate_sleep_latency(group[['in_bed_time', 'start_time', 'Type', 'sleep_state']]),
include_groups=False # 追加: グループ化列を適用操作から除外
).reset_index(name='sleep_latency')
# 結合して全データを含むデータフレームを作成
full_session_data = pd.merge(session_dates, sleep_times[['session_id', 'sleep_time']], on='session_id')
full_session_data = pd.merge(full_session_data, sleep_latency, on='session_id')
return full_session_data
def calculate_sleep_latency(group):
group = group.sort_values(by='start_time')
auto_sleep_times = group[(group['Type'] == 'Auto') & (group['sleep_state'] >= 4)]
if not auto_sleep_times.empty:
auto_sleep_time = auto_sleep_times['start_time'].iloc[0]
if pd.notna(group['in_bed_time'].iloc[0]) and group['in_bed_time'].iloc[0] <= group['start_time'].iloc[0]:
return (auto_sleep_time - group['in_bed_time'].iloc[0]).total_seconds() / 60
return np.nan
sleep_data_jst = convert_sleep_data_to_jst(sleep_data)
full_session_data = create_session_data(sleep_data_jst)
# 日付選択ウィジェット
date_picker = DatePicker(description='Select Date', disabled=False)
def on_prev_clicked(b):
date_picker.value = date_picker.value - pd.Timedelta(days=1) if date_picker.value else None
def on_next_clicked(b):
date_picker.value = date_picker.value + pd.Timedelta(days=1) if date_picker.value else None
button_prev = Button(description="Previous Day")
button_next = Button(description="Next Day")
button_prev.on_click(on_prev_clicked)
button_next.on_click(on_next_clicked)
display(HBox([button_prev, button_next]))
display(date_picker)
# タイムゾーンを確認して適切に日付を表示する関数
def set_plot_title(ax, session_id, sleep_data_jst):
jst = pytz.timezone('Asia/Tokyo')
session_data = sleep_data_jst[sleep_data_jst['session_id'] == session_id]
if not session_data.empty:
if session_data['start_time'].dt.tz:
start_time_jst = session_data['start_time'].min().astimezone(jst)
end_time_jst = session_data['end_time'].max().astimezone(jst)
else:
start_time_utc = session_data['start_time'].min().replace(tzinfo=pytz.utc)
end_time_utc = session_data['end_time'].max().replace(tzinfo=pytz.utc)
start_time_jst = start_time_utc.astimezone(jst)
end_time_jst = end_time_utc.astimezone(jst)
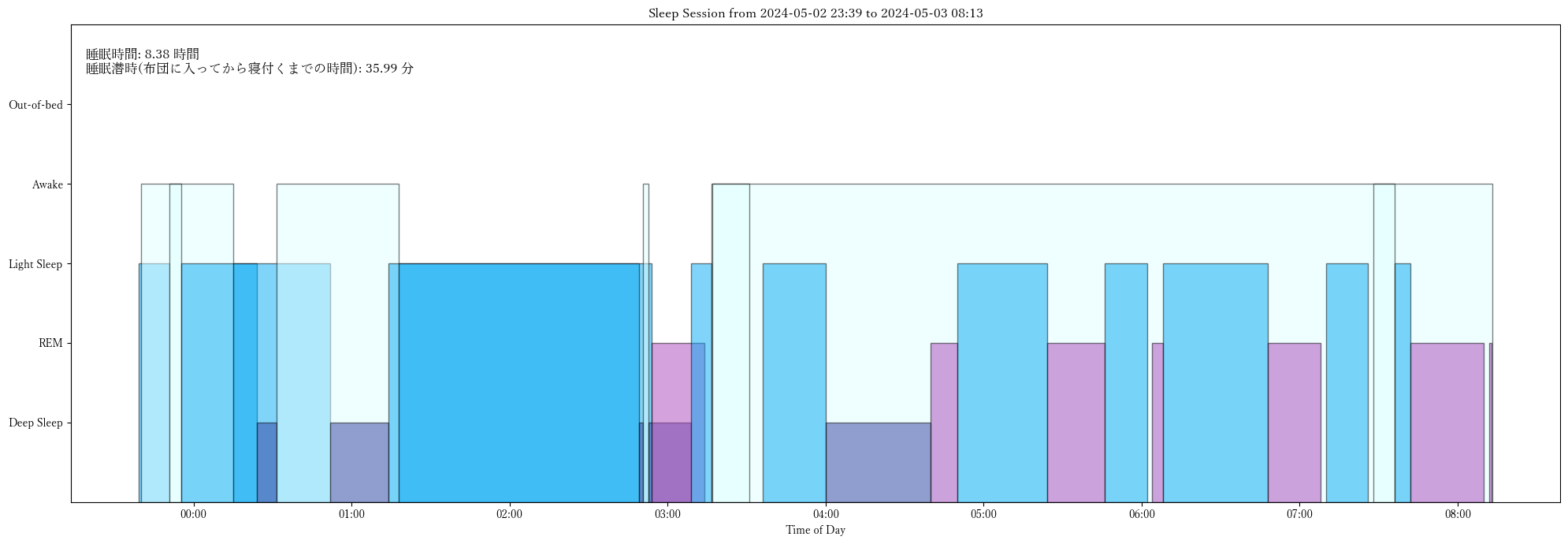
title = f"Sleep Session from {start_time_jst.strftime('%Y-%m-%d %H:%M')} to {end_time_jst.strftime('%Y-%m-%d %H:%M')}"
ax.set_title(title)
else:
ax.set_title("No data available for this session")
# キャプションを追加する関数
def add_caption(ax, session_id, full_session_data):
record = full_session_data[full_session_data['session_id'] == session_id].iloc[0]
# キャプションの初期部分
caption = f"睡眠時間: {record['sleep_time']:.2f} 時間\n"
# sleep_latencyがNaNやマイナスでない場合のみ追加
if pd.notna(record['sleep_latency']) and record['sleep_latency'] >= 0:
caption += f"睡眠潜時(布団に入ってから寝付くまでの時間): {record['sleep_latency']:.2f} 分"
ax.text(0.01, 0.95, caption, transform=ax.transAxes, fontsize=12, verticalalignment='top')
# 睡眠データをプロットする関数
def plot_sleep_data(session_id, sleep_data_jst, full_session_data):
session_info = full_session_data[full_session_data['session_id'] == session_id]
session_data = sleep_data_jst[sleep_data_jst['session_id'] == session_id]
if not session_data.empty:
# 日時データのタイムゾーンを確認し、日本時間に設定
if session_data['start_time'].dt.tz is None:
session_data['start_time'] = session_data['start_time'].dt.tz_localize('UTC').dt.tz_convert('Asia/Tokyo')
if session_data['end_time'].dt.tz is None:
session_data['end_time'] = session_data['end_time'].dt.tz_localize('UTC').dt.tz_convert('Asia/Tokyo')
fig, ax = plt.subplots(figsize=(20, 7))
stage_height = {3: 5, 1: 4, 4: 3, 6: 2, 5: 1, 10: 6}
stage_colors = {1: '#e0ffff', 3: '#ff5252', 4: '#03a9f4', 5: '#303f9f', 6: '#ab47bc', 10:'yellow'}
data_sources = session_data['data_source'].unique()
source_count = len(data_sources)
alpha_value = 1 / source_count if source_count > 0 else 1
# プロットの時間を日本時間に合わせて設定
for index, row in session_data.iterrows():
start_pos = mdates.date2num(row['start_time'])
duration = mdates.date2num(row['end_time']) - start_pos
ax.bar(x=start_pos, height=stage_height[row['sleep_state']], width=duration,
color=stage_colors.get(row['sleep_state'], '#FFFFFF'), edgecolor='black',
align='edge', alpha=alpha_value)
ax.xaxis_date(tz=timezone('Asia/Tokyo'))
ax.xaxis.set_major_locator(mdates.HourLocator(interval=1))
ax.xaxis.set_major_formatter(mdates.DateFormatter('%H:%M', tz=timezone('Asia/Tokyo')))
ax.set_ylim(0, 6)
ax.set_yticks([1, 2, 3, 4, 5, 6])
ax.set_yticklabels(['Deep Sleep', 'REM', 'Light Sleep', 'Awake', 'Out-of-bed', 'Mid Sleep Time'])
ax.set_xlabel('Time of Day')
set_plot_title(ax, session_id, sleep_data_jst)
add_caption(ax, session_id, session_info)
plt.tight_layout()
plt.show()
else:
print("No sleep data available for this session.")
# 日付変更時のイベントハンドラ
def on_date_change(change):
if change['new'] is not None:
selected_date = pd.to_datetime(change['new']).date()
session_id = next((sid for sid, date in full_session_data.set_index('session_id')['session_date'].items() if date == selected_date), None)
if session_id is not None:
plot_sleep_data(session_id, sleep_data_jst, full_session_data)
else:
print("No sessions found for this date.")
date_picker.observe(on_date_change, names='value')